NLP/CL Twitter Megathread
2017-04-08
How do people in Natural Language Processing (NLP) feel about their relation to (Computational) Linugistics (CL)? Emily M. Bender started this question with a simple poll:
This is a snapshot of the thread (573 tweets, edit on 2017-04-09: 588) that followed, observed through the beautiful Chrome Extension Treeverse. Siblings in the thread tree are roughly ordered by length of the branch to simplify reading, parts of the tree are extracted into new sections and 1/n-style tweets are grouped into a single block of text. Some tweets are reordered and reconnected to eliminate misunderstandings, allow some joining and thus ultimately improve readability. All tweets are clickable to get to the original. I omitted spam, jokes and other tweets that I thought added nothing to the discussion[1]. The sections headings and notes in italic font are my own additions.
As everyone will have their own highlights in this thread, I chose to display the whole thing. Although I would encourage everyone to skim everything, it may help you to jump to specific sections in this rough reflection of the thread:
- Discussion of results
- Lingustics Departments
- Focus ares in linguistics
- Linguistics classes
Discussion of results
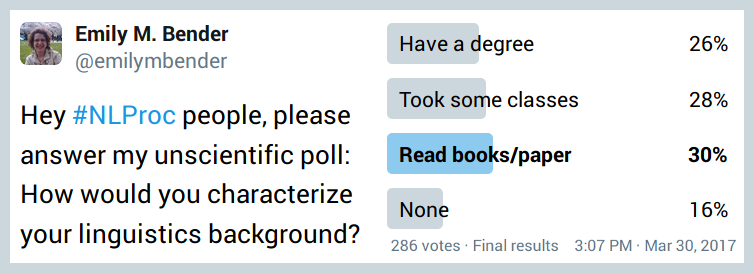
 Emily M. Bender (@emilymbender)
Time for results of my unscientific poll (thread):
In the 48 hours the poll was active, 286 twitter users responded.
Of those 286 twitter users, an unknown number are bots.
This does not count the replies that came in as tweets instead of votes.
Of the human subset of the twitter users, an unknown number identify as #NLProc people.
Of those 286 responses, an unknown number were stray clicks.
Of the human subset, an unknown number share my (or your) definitions of #NLProc and/or #linguistics.
The 286 responses (from bots and/or humans, #NLProc or otherwise) break down like this: [note: see top of this blog post]
Impressionistically, once the responses totaled >100, the percentages stayed fairly stable.
As is hopefully clear, one can’t draw any conclusions from a poll like this.
Nonetheless, I offer some discussion:
I hope that this is not in fact representative of the #NLProc community (as defined by e.g. submitting to *ACL venues).
Why? B/c it would contradict my charitable reading of the lack of ling. sophistication in much #NLProc work in submitted to/such venues.
I’d rather believe it’s bc the authors don’t know better, not bc they do have some background in linguistics and aren’t applying it.
Emily M. Bender (@emilymbender)
Time for results of my unscientific poll (thread):
In the 48 hours the poll was active, 286 twitter users responded.
Of those 286 twitter users, an unknown number are bots.
This does not count the replies that came in as tweets instead of votes.
Of the human subset of the twitter users, an unknown number identify as #NLProc people.
Of those 286 responses, an unknown number were stray clicks.
Of the human subset, an unknown number share my (or your) definitions of #NLProc and/or #linguistics.
The 286 responses (from bots and/or humans, #NLProc or otherwise) break down like this: [note: see top of this blog post]
Impressionistically, once the responses totaled >100, the percentages stayed fairly stable.
As is hopefully clear, one can’t draw any conclusions from a poll like this.
Nonetheless, I offer some discussion:
I hope that this is not in fact representative of the #NLProc community (as defined by e.g. submitting to *ACL venues).
Why? B/c it would contradict my charitable reading of the lack of ling. sophistication in much #NLProc work in submitted to/such venues.
I’d rather believe it’s bc the authors don’t know better, not bc they do have some background in linguistics and aren’t applying it.
 Alex Coventry (@AlxCoventry)
It would be great to see examples of research which would benefit from greater linguistic sophistication.
Alex Coventry (@AlxCoventry)
It would be great to see examples of research which would benefit from greater linguistic sophistication.
 Jason Baldridge (@jasonbaldridge)
Isn't it also the challenge of obtaining empirical results for deeper linguistic work? Need to create datasets, and
academic incentives work against creating such resources. It's hard, expensive, and generally low recognition.
Also, determining meaningful evaluation (linguistic & empirical) is hard, e.g. Which syntax formalism or analysis do you use?
Which is not to say we shouldn't try. I think the coming years will show need for deeper linguistics to make more progress.
Jason Baldridge (@jasonbaldridge)
Isn't it also the challenge of obtaining empirical results for deeper linguistic work? Need to create datasets, and
academic incentives work against creating such resources. It's hard, expensive, and generally low recognition.
Also, determining meaningful evaluation (linguistic & empirical) is hard, e.g. Which syntax formalism or analysis do you use?
Which is not to say we shouldn't try. I think the coming years will show need for deeper linguistics to make more progress.
 (((λ()(λ() 'yoav)))) (@yoavgo)
the problem with "took some classes" is that the intro classes (at least those I took) tend be very simplistic and rather trivial.
They really don't give a good impression. I only benefitted from ling courses when I started sampling "advanced classes" and seminars.
(also I guess your sample of the nlproc community is... a bit biased)
(((λ()(λ() 'yoav)))) (@yoavgo)
the problem with "took some classes" is that the intro classes (at least those I took) tend be very simplistic and rather trivial.
They really don't give a good impression. I only benefitted from ling courses when I started sampling "advanced classes" and seminars.
(also I guess your sample of the nlproc community is... a bit biased)
 Liling Tan (@alvations)
on the other side of the story, the linguists (myself included) might have also just "took some classes" on programming / machine learning 😁
Liling Tan (@alvations)
on the other side of the story, the linguists (myself included) might have also just "took some classes" on programming / machine learning 😁
 Hal Daumé III (@haldaume3)
I had opposite. The 2 courses I took in grad school were so technical & detailed it was neigh impossible to think how to apply (esp syntax).
I think if I'd been at UMD and had things like comp psycholinguistics, or neuroling, or pragmatics, it might've been different :/
Hal Daumé III (@haldaume3)
I had opposite. The 2 courses I took in grad school were so technical & detailed it was neigh impossible to think how to apply (esp syntax).
I think if I'd been at UMD and had things like comp psycholinguistics, or neuroling, or pragmatics, it might've been different :/
Lingustics Departments
 brendan o'connor (@brendan642)
do many postsecondary institutions even have linguistics depts? (lsa type linguists, not language depts).
our cs dept gets hundreds of (often intl) grad applicants wanting to research nlp. (i'm sure more elsewhere.) very few have ling background.
i'm not sure whether they all could find smart, empirical, yet theoretically grounded ling courses in ugrad even if they wanted.
brendan o'connor (@brendan642)
do many postsecondary institutions even have linguistics depts? (lsa type linguists, not language depts).
our cs dept gets hundreds of (often intl) grad applicants wanting to research nlp. (i'm sure more elsewhere.) very few have ling background.
i'm not sure whether they all could find smart, empirical, yet theoretically grounded ling courses in ugrad even if they wanted.
Emily M. Bender (@emilymbender)
http://www.linguisticsociety.org/programs
Focus areas in linguistics
 Anders Søgaard (@soegaarducph)
Nice poll, nice thread! My 10 cents: more value in {socio-, psycho-, typological} linguistics than in 101 run-through of theories.
Anders Søgaard (@soegaarducph)
Nice poll, nice thread! My 10 cents: more value in {socio-, psycho-, typological} linguistics than in 101 run-through of theories.
 Shlomo Argamon (@ShlomoArgamon)
Intro courses should do more methodology and "linguistic thinking" than theory survey.
Shlomo Argamon (@ShlomoArgamon)
Intro courses should do more methodology and "linguistic thinking" than theory survey.
Hal Daumé III (@haldaume3)
agree: I think the more experimental the topic, the more relatable, useful, interesting it is to NLP (but this is a massive personal bias)
Anders Søgaard (@soegaarducph)
Compared to the bias in theoretical linguistics, I'm sure it's negligible. :)
Hal Daumé III (@haldaume3)
I think I was lucky to have gotten exposed to LFG, typology, etc. as an UG before I went to grad school & got hammered with Chomsky :)
Emily M. Bender (@emilymbender)
I think the problem with the less useful subfields of linguistics is that they are relatively unconcerned with actual data.
So syntax that actually cares about getting the details right (and accounting for data) should also be useful & relatable.
Syntax that is only concerned with theory building ... is a large part of the problem. But that doesn't let NLPers off the hook!
 Yonatan Belinkov (@boknilev)
I think the competence/performance distinction is making a large part of ling. irrelevant for NLP
Yonatan Belinkov (@boknilev)
I think the competence/performance distinction is making a large part of ling. irrelevant for NLP
Mathieu Morey (@moreymat)
This is a real issue for syntax but not so much for semantics or discourse. Yet most NLPers pay little to no attention to data nor theory
(((λ()(λ() 'yoav)))) (@yoavgo)
the problem with semantics is that the main message I get from modern sem papers is "too complex, too hard, don't bother, won't work".
Mathieu Morey (@moreymat)
I have the same impression, but a lot of NLP people show total ignorance (or dispense) from basic semantics eg. consistency, inference.
what's the pt of improving predictn of discourse structures with relations that are so coarse-grained they don't support any inference?
Approx. representations initially introduced for downstream application make no sense in purely intrinsic eval. But easier, so people do it.
Linguistics classes
Hal Daumé III (@haldaume3)
I had opposite. The 2 courses I took in grad school were so technical & detailed it was neigh impossible to think how to apply (esp syntax).
I think if I'd been at UMD and had things like comp psycholinguistics, or neuroling, or pragmatics, it might've been different :/
 Ryan Cotterell (@_shrdlu_)
I agree with Hal. I took 6 graduate linguistic classes as an undergrad and most are irrelevant to current NLP research.
Ryan Cotterell (@_shrdlu_)
I agree with Hal. I took 6 graduate linguistic classes as an undergrad and most are irrelevant to current NLP research.
(((λ()(λ() 'yoav)))) (@yoavgo)
yes, my syntax course started ok but when they started talking about ECM and vp-shells and stuff I kinda lost interest.
On the other hand the "intro to ling" course talked about trees in a super superficial level, and spent forever talking about "logic".
 Yuval Pinter (@yuvalpi)
TAU offers "foundations of theoretical ling" which is just the midpoint you're looking for. Post-intro, pre-ECM.
Yuval Pinter (@yuvalpi)
TAU offers "foundations of theoretical ling" which is just the midpoint you're looking for. Post-intro, pre-ECM.
 Simonson (@thedansimonson)
I feel like my syntax class could have been more useful as a breadth-based approaches to structure rather than a depth into GB (in 2011)
Simonson (@thedansimonson)
I feel like my syntax class could have been more useful as a breadth-based approaches to structure rather than a depth into GB (in 2011)
 ts waterman (@tswaterman)
Yeah, GB is not really much of an applicable computational theory...
ts waterman (@tswaterman)
Yeah, GB is not really much of an applicable computational theory...
Hal Daumé III (@haldaume3)
agreed (2001) :P
(((λ()(λ() 'yoav)))) (@yoavgo)
I feel that the very basic courses were too basic, then there were the super technical and useless, and the seminars that were good and
actually explained to me how these weird people think, and some of their methodology.
and the psycholing stuff was the best.
Simonson (@thedansimonson)
I got little exposure to psycholing in my coursework, but that seems to be a recurring theme in this thread. any reading recommendations?
Hal Daumé III (@haldaume3)
LING 640/641 at UMD are really good (Naomi Feldman and @ColinPhillips2). I think both syllabi are online.
Hal Daumé III (@haldaume3)
agreed. I thought back then, because NLP is so obsessed w parsing, that syntax sd be useful, but I'm not sure, even if I cared abt parsing
(((λ()(λ() 'yoav)))) (@yoavgo)
I think the core concepts are important, if you work with syntax. Something like the intro chapters of a good book like "Syntactic Theory"[meaning Sag, Wasow & Bender 2003; omitting the following question and "yes."-reponse]
But a syntax course as usually thought is a turn-off overkill in most cases
 Rob Malouf (@robmalouf)
Take a look at Maggie Tallerman's Understanding Syntax.
Rob Malouf (@robmalouf)
Take a look at Maggie Tallerman's Understanding Syntax.
Syntactic grammar formalisms
(((λ()(λ() 'yoav)))) (@yoavgo)
[...] if there was a version of [Sag, Wasow & Bender 2003] without the feature structures details (or with less) it'd be amazing!
Emily M. Bender (@emilymbender)
Not sure what good such a text would do. The point of HPSG afterall is that it actually works and is formalized enough to test.
Anders Søgaard (@soegaarducph)
Do you mean HPSG as such is falsifiable? I would think not. & definitely not in a computationally feasible way. ( ☂️+🥛=? )
Emily M. Bender (@emilymbender)
Any given analysis in HPSG is falsifiable. We do that all the time in grammar engineering! As a theory, probably not.
Anders Søgaard (@soegaarducph)
Gotcha, but doesn't that make linguistic theories about as important as choice of programming language? :)
 Asad Sayeed (@asayeed)
yeah a formalism is not (by virtue of being a formalism) a theory.
if your formalism requires X as an axiom, then X is the theory.
so eg if your formalism requires recursion be a fundamental property of lg...
...then it's the recursion that's the theory, the formalism is just notation
Asad Sayeed (@asayeed)
yeah a formalism is not (by virtue of being a formalism) a theory.
if your formalism requires X as an axiom, then X is the theory.
so eg if your formalism requires recursion be a fundamental property of lg...
...then it's the recursion that's the theory, the formalism is just notation
Rob Malouf (@robmalouf)
That's why I stopped doing HPSG.
That syntax can or should "work" depends on all kinds of Chomskyan assumptions that I don't think we should be making, either in lx or NLP.
(My point just being that there's still a lot of disagreement even among linguists about what some might consider pretty basic stuff.)
Emily M. Bender (@emilymbender)
True --- but that shouldn't stop #NLPRoc folks from engaging with linguists and getting some kind of understanding of the data they work w/.
 Stefan Müller (@StefanMuelller)
There is the beginning of something like this. I call it #HPSGlight: http://hpsg.fu-berlin.de/~stefan/Pub/germanic.html … #syntax #germanic
I think all the informal crowd (#GB, #Minimalism) has an unfair advantage. One should have a defined way like #HPSGLight and
some defined mapping to a real formalized theory. Germanic book has light description + implementation. Everyb. can see the real thing.
Stefan Müller (@StefanMuelller)
There is the beginning of something like this. I call it #HPSGlight: http://hpsg.fu-berlin.de/~stefan/Pub/germanic.html … #syntax #germanic
I think all the informal crowd (#GB, #Minimalism) has an unfair advantage. One should have a defined way like #HPSGLight and
some defined mapping to a real formalized theory. Germanic book has light description + implementation. Everyb. can see the real thing.
(((λ()(λ() 'yoav)))) (@yoavgo)
This looks great, really! but alas still not what I am looking for :( that is, not suitable for cs/nlp people who want breadth, not depth.
Stefan Müller (@StefanMuelller)
Depending on how much time you have in the curriculum you should do one in depth course.
Otherwise they do not understand the depth of the problem.
Quote Martin Kay around 2000: #MachineTranslation is not a problem. It is a big problem!
(((λ()(λ() 'yoav)))) (@yoavgo)
Yes, but unfortunately I don't have time in the curriculum :( I want something I can give a masters/PhD to read, and that they actually do.
(or for NLP researchers who want to know more about syntax but won't take a course)
I think book that lists interesting/challenging language constructs, and show how they are tackled in the diff formalisms, is really needed
(200pp book, 300pp tops)
Hal Daumé III (@haldaume3)
one thing that IIRC Nizar Habash has done in his NLP classes is each student has to present 10 mins (or something) on some language
the idea being to introduce constructions, etc., that are "unusual" from the predominantly Indo-European perspective that we often have.
it's not teaching people Ling, but it's teaching some things you'd have to deal with in linguistically broad systems https://sites.google.com/site/comse6998machinetranslation/home#LinTen …
ht @MarineCarpuat who told me about this and who I think has tried it in her classes
Yuval Marton (@yuvalmarton)
+1 for @nyhabash L10. I adopted it too in my classes in 2016 and now.
I loved my (ultra Chomskian) syntax classes (Howard Lasnik, Norbert Hornstein ~2004/5). + late Tanya Reinhart in undergrad (~1867 BC).
But had to find own way to apply (to SMT). More HPSG etc woulda been great too.
Everything is connected and difficult
Stefan Müller (@StefanMuelller)
The fun part is that everything interacts with everything. If you do not understand the core you will never understand the funny stuff.
I wrote about the concept of coriness (Kernigkeit). #core/#periphery Sorry, in German: http://hpsg.fu-berlin.de/~stefan/Pub/kernigkeit.html
Emily M. Bender (@emilymbender)
As @StefanMuelller says: The "here's how framework X does it" would make no sense w/o understanding how X handles other things.
So it sounds like @yoavgo is asking for a way for his students to know what syntacticians know w/o studying it like syntacticians do.
(((λ()(λ() 'yoav)))) (@yoavgo)
I don't want / need my students to know what syntacticians know, just a small subset. But I'll continue this topic later when more focused.
Stefan Müller (@StefanMuelller)
OK, but then *you* have to know it all to be able to choose.
(((λ()(λ() 'yoav)))) (@yoavgo)
Not really, but, again, more later ;)
Yuval Pinter (@yuvalpi)
Isn't it fair though? Biologists have a lot of chemistry knowledge they learned more superficially than chemists do.
Emily M. Bender (@emilymbender)
I contend that knowing the phenomena is analogous to that; not knowing the workings of various frameworks' analyses of the phenomena.
Yuval Pinter (@yuvalpi)
Even knowing the right variety of phenomena would be enough then - with emphasis on crossling variance.
Syntax classes I know follow the chain (phenomenon->theory->)+ already.
Emily M. Bender (@emilymbender)
... which is the approach I take in my book, but @yoavgo wants something more/diff :)
(((λ()(λ() 'yoav)))) (@yoavgo)
for syntax specifically, I want something diff, yes. for general linguistics intro, I want something more ;) (more explicit motivations)
like, what I am missing with the book when giving it to CS people to read, is that they don't understand why they should care about this.
for me (and I am sure that for you, @emilymbender as well, and even more so) the connection is clear. but it turns out not to be.
for example in #45, "syntax provides scaffolding for semantics". I found that many don't understand what this means w/o few exp examples
Emily M. Bender (@emilymbender)
I can see how that one is a little dense ... it was meant as part of an intro. In a sense, the ex are in things #51-97.
But also: The new volume I'm working on with Alex Lascarides will get into the semantic side of all of that much more.
Syntactic grammar formalisms, continued
Emily M. Bender (@emilymbender)
Not sure what good such a text ["without the feature structures details", @yoavgo] would do. The point of HPSG afterall is that it actually works and is formalized enough to test.
(((λ()(λ() 'yoav)))) (@yoavgo)
I guess my angle is that I don't care much about HPSG (or any other specific theory). Rather than describing a specific implementation
In relative depth, I'd rather see a formalism independent discussion of what are the problems that need solving, and then perhaps a broad
but shallower discussion of various solutions, in different implementations (some CCG, some HPSG, some TAG...)
ts waterman (@tswaterman)
Yes - you need to lay out "these are the phenomena we need to account for". As Emily said, simple linear structure isn't it
Stefan Müller (@StefanMuelller)
Yes, but this is the GT book: #Passive, #Scrambling, #Extraction, #Adjuncts, #Semantics, #syntax, #aquisition http://langsci-press.org/catalog/book/25
Yuval Pinter (@yuvalpi)
Yes. I feel the main skill my deg gave me was the ability to think of example issues for given problem (interesting test cases/edge cases).
Also: typology typology typology
 Matthew Honnibal (@honnibal)
You do need to see good coverage though, or it's like comparing proglangs on hello world. For me the best resource was the xtag grammar.
Matthew Honnibal (@honnibal)
You do need to see good coverage though, or it's like comparing proglangs on hello world. For me the best resource was the xtag grammar.
 Fred (@fmailhot)
Maggie Tallerman's book might be a good candidate for this (or Pullum & Huddleston if you have a lot of time & shelf space!)
Fred (@fmailhot)
Maggie Tallerman's book might be a good candidate for this (or Pullum & Huddleston if you have a lot of time & shelf space!)
Emily M. Bender (@emilymbender)
I can see how that might be a useful book. I'm not going to write it though.
(((λ()(λ() 'yoav)))) (@yoavgo)
I guess I won't be writing it either (I am really under qualified) but hopefully someone will ;)
(a book without any given theory, that only highlights problems, could also be nice, though serving a different purpose)
 Jeremy Kahn (@trochee)
a "data structures for linguistic theory" resource?
you know, if there were a working code structure for OT, it might make me take that a lot more seriously too.
Jeremy Kahn (@trochee)
a "data structures for linguistic theory" resource?
you know, if there were a working code structure for OT, it might make me take that a lot more seriously too.
Fred (@fmailhot)
http://www.linguistics.ucla.edu/people/hayes/otsoft/
Emily M. Bender (@emilymbender)
There is! I'll dig up refs for you when I'm back at my desk. It's finite state, too.
[...]
Here's the paper I was thinking of (Karttunen 1998) http://www.aclweb.org/anthology/W98-1301
That's for the general constraint algorithm. Implementing specific constraints is a separate issue, but I doubt that's what you worry about
Jeremy Kahn (@trochee)
I can imagine an application for OT formalism in SRL ranking, so, neat.
Jeremy Kahn (@trochee)
it's been my experience that the general constraint algorithm has always been the rug under which problems in the specific are swept
Yuval Pinter (@yuvalpi)
I think Bruce Tesar also had something along the line. (Also: "proper treatment of ..." - clear indication this was meant for linguists)
 Kristine Yu (@linguist_krisyu)
I've been having a lot of fun building on that work in trying to better understand phonological grammars!! https://github.com/krismyu/smo-constituency-feet
There's a small typo in the code in Karttunen 98; I can send a working version of the xfst code to anyone who wants to play with it.
Kristine Yu (@linguist_krisyu)
I've been having a lot of fun building on that work in trying to better understand phonological grammars!! https://github.com/krismyu/smo-constituency-feet
There's a small typo in the code in Karttunen 98; I can send a working version of the xfst code to anyone who wants to play with it.
 Djamé (@zehavoc)
Too bad it's in French, "les nouvelles syntaxes" (new syntaxes) from Anne Abeillé is exactly that: issues+solution in GPSG, LFG, HSPG, TAG
https://www.amazon.com/nouvelles-syntaxes-Grammaires-dunification-Linguistique/dp/2200210965/ref=sr_1_2?ie=UTF8&qid=1491174102&sr=8-2&keywords=les+nouvelles+syntaxes … (new edition removed GPSG though)
If one day I have the funding, I'll try to hire some people and write two more chapters : one for CCGs, one for Minimalist grammars
Djamé (@zehavoc)
Too bad it's in French, "les nouvelles syntaxes" (new syntaxes) from Anne Abeillé is exactly that: issues+solution in GPSG, LFG, HSPG, TAG
https://www.amazon.com/nouvelles-syntaxes-Grammaires-dunification-Linguistique/dp/2200210965/ref=sr_1_2?ie=UTF8&qid=1491174102&sr=8-2&keywords=les+nouvelles+syntaxes … (new edition removed GPSG though)
If one day I have the funding, I'll try to hire some people and write two more chapters : one for CCGs, one for Minimalist grammars
(((λ()(λ() 'yoav)))) (@yoavgo)
my suggestion: forgo the minimalist chapter, and invest in English translation instead.
Djamé (@zehavoc)
I'm surprised no one has done the same work for English as well but I'm probably just not aware of it.
regarding MGs, I'd like to understand them better. So some comparative syntax could be cool.
[...]
Can't believe i forgot about it, of course there is one (and it's free) https://hpsg.fu-berlin.de/~stefan/Pub/grammatical-theory.html
Book: "Grammatical theory"
Djamé (@zehavoc)
Can't believe i forgot about it, of course there is one (and it's free) https://hpsg.fu-berlin.de/~stefan/Pub/grammatical-theory.html
brendan o'connor (@brendan642)
i hadn't seen this before - looks great. thanks for the pointer.
 Grzegorz Chrupała (@gchrupala)
wow ten formalisms?
Grzegorz Chrupała (@gchrupala)
wow ten formalisms?
(((λ()(λ() 'yoav)))) (@yoavgo)
Skimmed it---looks great but waay too intense for an NLP/CS student who just needs the basics
Djamé (@zehavoc)
we should ask @StefanMuelller if he has some lighter material for nlp students
Stefan Müller (@StefanMuelller)
Well, I gess the GT book is as light as it gets. This is really simlified. I did it with BA students for German language.
If future German teachers get it, NLP students will get it as well. Slides are here: http://hpsg.fu-berlin.de/~stefan/Pub/grammatical-theory.html
(((λ()(λ() 'yoav)))) (@yoavgo)
Yes, it is great on that front --- but only HPSG, right?
Djamé (@zehavoc)
I found this from an Essli 2006 advanced class by Julia H., Miayo, J. van Genabith covers TAG, LFG, HSPG, CCG http://pauillac.inria.fr/~seddah/Malaga06_Josef.pdf
(((λ()(λ() 'yoav)))) (@yoavgo)
This, like most of them, describes the how, not the why.
Djamé (@zehavoc)
Why do they provide such analysis or why do these formalisms exist ?
if the former, it's like in treebanking: why some have DTs and others NPs, why fo some favors Verbal Nucleus over NPs? There're explanations
but they all need like 2 sentences of TL;DR for the how and 10 pages for the justifications.
Syntactic grammar formalisms, continued, again
(((λ()(λ() 'yoav)))) (@yoavgo)
I guess my angle is that I don't care much about HPSG (or any other specific theory). Rather than describing a specific implementation
In relative depth, I'd rather see a formalism independent discussion of what are the problems that need solving, and then perhaps a broad
but shallower discussion of various solutions, in different implementations (some CCG, some HPSG, some TAG...)
 Good Content Creator (@wellformedness)
1 form of syntax pedagogy (and what I encountered at Penn) is just "phenomena plus simple forms of the GB-ish analysis".
*very few* linguists know [GH]PSG, TAG, CCG. If you value communication with them you should target GB-to-minimalist formalisms instead.
Good Content Creator (@wellformedness)
1 form of syntax pedagogy (and what I encountered at Penn) is just "phenomena plus simple forms of the GB-ish analysis".
*very few* linguists know [GH]PSG, TAG, CCG. If you value communication with them you should target GB-to-minimalist formalisms instead.
(((λ()(λ() 'yoav)))) (@yoavgo)
Communicating with GB syntacticians isn't my primary objective.
 Robert Henderson (@rhenderson)
It's much more fun to talk with semanticists :D
Robert Henderson (@rhenderson)
It's much more fun to talk with semanticists :D
Good Content Creator (@wellformedness)
but aren't you and @JessicaFicler fixing the (GB-indebted) PTB annotations to be more GB-like? ;)
(((λ()(λ() 'yoav)))) (@yoavgo)
Not really, in the sense that Jessica don't know GB at all, and I also don't really know it. (we do fix some stuff there though)
Good Content Creator (@wellformedness)
imo there are probably many more changes like that one that bring the trees closer to "good" analyses---do you have more changes in store?
(((λ()(λ() 'yoav)))) (@yoavgo)
We did two diff kinds of changes. The 1st took "precise" annotation that was hard for CFGs to work with, and created a less precise but
more "computable" one. So it "ruined" the annotation in a sense. The 2nd added info that wasn't in the original annotation.
We may be doing more of the later at some point.
Emily M. Bender (@emilymbender)
Syntax isn't all of linguistics, you know. Also: it seems perverse to skip over the compling friendly formalisms (and linguists)
and go straight for the syntax class that has turned off so many NLPers (at least as evidenced by early tweets in this thread^H^H snarl)
Communication with and inside linguistics
Good Content Creator (@wellformedness)
I admit they could be better designed for that audience! But I don't agree with yr dichotomy "computational friendly formalisms" vs. "other"
Emily M. Bender (@emilymbender)
There are a few people who are interested in implementable MP --- e.g. http://search.proquest.com/docview/1868419023?pq-origsite=gscholar
But for the most part, people working in MP that I've spoken with (and remember, I'm a linguist) don't want to make it precise enough
Good Content Creator (@wellformedness)
Right, it's all computational, some people just care more than others. (But Ed Stabler and crew care a lot about MP w.r.t this)
Good Content Creator (@wellformedness)
do you see that as a problem for cross-field communication? i guess i don't.
Emily M. Bender (@emilymbender)
In principle, no. In practice yes --- most neg exp I see described involve NLPers coming up against MP.
Good Content Creator (@wellformedness)
So as to provide a positive example, Beatrice Santorini's (of PTB fame) online syntax 'textbook' is a rather accessible intro to GB-lite.
http://www.ling.upenn.edu/~beatrice/syntax-textbook/ …. It also has a computational impl of a bit of X-bar stuff.
Good Content Creator (@wellformedness)
I'm focusing on the q of what syntax NLPers need to do good work and communicate w linguists. HPSG won't help because so few linguists use.
That said, they're free to go learn how (e.g.) HPSG or TAG does raising! It's cool! But if they want to talk about raising with linguists...
(((λ()(λ() 'yoav)))) (@yoavgo)
For communication, they should know what raising is. That's enough.
Good Content Creator (@wellformedness)
i maintain also that the easiest way to "know" what it is is to read the Santorini chapter on it. it's short.
Emily M. Bender (@emilymbender)
GB/MP ain't gonna help you talk to typologists, or sociolinguists, or phonologists...
Good Content Creator (@wellformedness)
Disagree. Syntactic variation rsrch is overwhelmingly (informally) GB/MP. (And I'm *still* not talking about phonology.)
as for phonology, there are many good options; as you probably know Google runs on 100s of 1000s of A -> B / C__D rules compiled into WFSTs.
brendan o'connor (@brendan642)
WFSTs for speech, or something else? not always clear how google/etc use nlp - references/details are very helpful to motivate teaching
Good Content Creator (@wellformedness)
WFSTs are still SOTA in ASR (with some hybridization from NNs). But no rewrite rules there.
Rewrite rule-based WFST speech text normalization at Google are described in a bunch of papers. (One or two by me; many by Richard Sproat).
there may also be stuff for various IE/IR applications but i don't work in that area so i wouldn't know
http://ieeexplore.ieee.org/abstract/document/6639276/?reload=true https://www.transacl.org/ojs/index.php/tacl/article/view/897/213 https://www.cambridge.org/core/journals/natural-language-engineering/article/kestrel-tts-text-normalization-system/F0C18A3F596B75D83B75C479E23795DA https://arxiv.org/abs/1611.00068 https://arxiv.org/abs/1609.06649
brendan o'connor (@brendan642)
awesome, thanks!
Who cares about syntax?
Hal Daumé III (@haldaume3)
agreed, but how many people actually work on syntax? :/
(((λ()(λ() 'yoav)))) (@yoavgo)
even if you only work *with* syntax (as features, in MT...), or do anything beyond bag of words.
Hal Daumé III (@haldaume3)
i agree core concepts enough, but also think it's sufficiently small you can easily cover it in an intro NLP class & don't need separate
(((λ()(λ() 'yoav)))) (@yoavgo)
You can, but you often don't. No need for sep course, but point to first chapters of good intro book.
(similar for Typology btw. Need to know basics, not more)
Jason Baldridge (@jasonbaldridge)
Linguistics is more expansive than just MIT core. Sounds, semantics & social, oh my!
 Sabrina J. Mielke (@sjmielke)
Anyone know of a good list of such "read-chapter-1" books for beginning #NLProc students? (in add. to "Syntactic Theory" mentioned above)
Sabrina J. Mielke (@sjmielke)
Anyone know of a good list of such "read-chapter-1" books for beginning #NLProc students? (in add. to "Syntactic Theory" mentioned above)
Hal Daumé III (@haldaume3)
I like beg of "Rhyme and Reason" (Uriagereka) for syntax stuff if you want someone to try to convince you of minimalism :) (ht @asayeed)
Emily M. Bender (@emilymbender)
"read-all", not "read-ch-1", but this is why I wrote: http://www.morganclaypool.com/doi/abs/10.2200/S00493ED1V01Y201303HLT020 … (NB: Free ebook if your institution subscribes)
Sabrina J. Mielke (@sjmielke)
Read it some time ago, great "read-all", for sure! I remember it as mostly highlighting difficult (and unexpected) phenoma though,
and less "here's how this all could work / be represented" (which is probably a pretty questionable objective though...).
Emily M. Bender (@emilymbender)
For one thing "here's how this could all work" for that many phenomena would be huge! Esp bc a good ling theory is internally consistent.
But also: I figured what was missing was an introduction to the phenomena that wasn't buried in theory, so the #NLProc ppl don't have to dig
Hal Daumé III (@haldaume3)
agreed. at end of day, 10% of 10 classes is useful. prob better that diff ppl know diff things (based on interests) & then talk :)
(((λ()(λ() 'yoav)))) (@yoavgo)
Yup!
I think I find it useful to go for linguistics for problems. Not for solutions, because, well, they don't really have them.
Djamé (@zehavoc)
it's often a choice between "this works with spherical chickens in a vaccum" and "we need to redefine what's a char first, up to meaning"
Hal Daumé III (@haldaume3)
q2Emily: is there a clustering of things that peeve you that ppl don't seem to know? feel free to pick on my papers for ex if you like :)
maybe the answer is "Yes & I wrote a book on it" & then that's a fine answer too :)
Book: "Linguistic Fundamentals for Natural Language Processing"
Emily M. Bender (@emilymbender)
So on one level, Yes and I wrote a book on it. ;-) That was certainly the motivation for the book & tutorial it was based on.
But to condense to a few tweets, it's things like: (1) Language has structure beyond linear order of words.
(2) That structure is useful to leverage if we're interested in extracting meaning.
(3) That structure is useful also in doing error analysis.
(4) Linguistic (conventional) meaning is different from speaker (occasion) meaning.
(On (4), see: http://aclweb.org/anthology/W/W15/W15-0128.pdf)
(5) The structure of a given language is fairly constant across genres (though not perfectly so).
(6) But languages vary in the structures that they use (though not unboundedly so).
(On (6), see http://journals.linguisticsociety.org/elanguage/lilt/article/view/2624.html)
(((λ()(λ() 'yoav)))) (@yoavgo)
My problem with Emily's book is that it is very informative, but lacks higher level motivation & discussion (that ling intro books provide)
otoh, those other books completely fail on the concise-and-informative front.
Emily M. Bender (@emilymbender)
Hm I thought the motivation was implicit, i.e. that it makes sense to understand the domain you're trying to model.
But I'm curious what else you'd like to see. One reason: I'm working on a second volume in that set, focusing on semantics & pragmatics.
(Not on my own, though! Co-authored with Alex Lascarides.)
(((λ()(λ() 'yoav)))) (@yoavgo)
Should be made more explicit I guess. And also more focused for each topic. We care about morphology because. We care about syntax because.
Emily M. Bender (@emilymbender)
Hm, I tried to do some of that, though it's largely after introducing each topic, but connecting to NLP tasks...
(((λ()(λ() 'yoav)))) (@yoavgo)
not sure connecting to tasks is what I am after... again I kind of liked the synt theory intro approach.
Emily M. Bender (@emilymbender)
As for examples of papers to pick on: Any paper that claims language independence because they didn't use any linguistic resources.
Ryan Cotterell (@_shrdlu_)
But they are right that their method can be used on any language and is in that sense independent. It's just performance may vary.
Hal Daumé III (@haldaume3)
I think Emily's point was that that's a useless claim. I can run 'bzip2' on any language but that doesn't mean squat.
(((λ()(λ() 'yoav)))) (@yoavgo)
not true. can't run bzip2 on sign languages and other non-written varieties! (I'm learning!)
Hal Daumé III (@haldaume3)
you can run it on video/audio files or gesture files. it probably won't compress video/audio very well tho :P
Claims, papers and reviewing
Emily M. Bender (@emilymbender)
As for examples of papers to pick on: Any paper that claims language independence because they didn't use any linguistic resources.
Hal Daumé III (@haldaume3)
I agree & am sure I've failed. I think this is part of a big problem: we _love_ to overclaim in general, & never box in our results.
Emily M. Bender (@emilymbender)
Yeah, I've noticed that that is typical of CS, and it bugs me every time :)
Hal Daumé III (@haldaume3)
it really hit home for me a few yrs ago in a seminar Naomi Feldman, Ellen Lau and I co-taught on prediction (brain vs machine).
we'd read these neuroling papers & they're SO careful to specify conditions under which they expect results to generalize and _undersell_.
then we'd read a CS paper and it's like "nope no assumptions everything is perfect this will work every time no joke." :)
 Aditya Bhargava (@rightaditya)
This really bothered me when I first got in to the field. My first draft of my first paper listed many caveats about the results :/
Aditya Bhargava (@rightaditya)
This really bothered me when I first got in to the field. My first draft of my first paper listed many caveats about the results :/
Emily M. Bender (@emilymbender)
I'm planning on writing a paper about "data statements" for NLP with Batya Friedman. It's a major issue for bias/exclusion, too.
We'll probably get to it this summer...
Hal Daumé III (@haldaume3)
what does "data statements" mean?
Emily M. Bender (@emilymbender)
Something that the psychologists & HCI folks & others do where they lay out the details of their data & its limitations.
Hal Daumé III (@haldaume3)
ah cool. can't wait to see it :)
Hal Daumé III (@haldaume3)
broad linguistic applicability (when tested on one or two families) is an example of overclaiming; there are tons more
eg in ML "my algorithm beat yours on three datasets --> my algorithm will beat yours on any conceivable other dataset" uhm no.
(((λ()(λ() 'yoav)))) (@yoavgo)
in a latest ACL review (paper accepted) we got "they claim sota results, but it is only so on the majority of the datasets they test"

Hal Daumé III (@haldaume3)
that wasn't me, but I do point things like this out in reviews. i think it's pretty rare they get adopted in CR though.
(((λ()(λ() 'yoav)))) (@yoavgo)
umm... the paper was kinda clear on where we succeed and where less so (as the rev said). it bothered them that we even reported this result
Hal Daumé III (@haldaume3)
that's dumb (I think? hard to be sure without more context)
(((λ()(λ() 'yoav)))) (@yoavgo)
I vote for dumb, but I'm biased
(((λ()(λ() 'yoav)))) (@yoavgo)
I don't like to over claim but I do like having papers accepted.
Emily M. Bender (@emilymbender)
How do you treat non-overclaiming papers when you review?
(((λ()(λ() 'yoav)))) (@yoavgo)
I am usually very supportive, unless it goes to the other extreme (as some ling folks do) and doesn't make any explicit claim whatsoever.
Hal Daumé III (@haldaume3)
<cynical_hal> overclaim in the submission, fix in camera ready </cynical_hal>
Emily M. Bender (@emilymbender)
<optimist_Emily>Be the change you want to see in the revising process! ... not closing the bracket, b/c I'm always an optimist ;-)
Hal Daumé III (@haldaume3)
I remember discussions when review form added "does this paper clearly state limitations" as a field, but I don't think it was taken srsly
Emily M. Bender (@emilymbender)
It'll be an uphill battle for sure.
(((λ()(λ() 'yoav)))) (@yoavgo)
I always have so many plans for how things will change for camera ready... somehow they seldom get implemented :/
Hal Daumé III (@haldaume3)
low incentive. just write another paper :)
Ryan Cotterell (@_shrdlu_)
Or, you could write an appendix: http://aclweb.org/anthology/attachments/N/N15/N15-1094.Notes.pdf
Appendices
Ryan Cotterell (@_shrdlu_)
Or, you could write an appendix: http://aclweb.org/anthology/attachments/N/N15/N15-1094.Notes.pdf
(((λ()(λ() 'yoav)))) (@yoavgo)
cool! but these should really be attached to the paper, so people could actually find them.
Ryan Cotterell (@_shrdlu_)
Well, page limits are strictly enforced. Science comes in exactly two sizes: 5 and 9 pages (for camera ready) -- at least in our community.
(((λ()(λ() 'yoav)))) (@yoavgo)
I think conferences should allow unlimited appendices. some do. we did it at conll last year. I hope others will follow.
Hal Daumé III (@haldaume3)
agreed. thing that bugs me tho: having 2 vers of paper. one is arxiv ver that's 20pg, integrated; the other is conf ver that's 8+12, choppy.
Ryan Cotterell (@_shrdlu_)
They are unlimited. They are just under notes in the ACL anthology.
(((λ()(λ() 'yoav)))) (@yoavgo)
yes. no one ever looks there. put it in the same pdf, preferably before the references.
Hal Daumé III (@haldaume3)
needs to be part of same pdf imo
Ryan Cotterell (@_shrdlu_)
I completely agree and the author of most of that appendix (Jason Eisner) would likely also strongly agree :P
Applicability of algorithms on other languages
Emily M. Bender (@emilymbender)
As for examples of papers to pick on: Any paper that claims language independence because they didn't use any linguistic resources.
(((λ()(λ() 'yoav)))) (@yoavgo)
well. the algorithm could be *applied* to any language without further effort.
Emily M. Bender (@emilymbender)
... which I contend is a completely uninteresting claim. And furthermore, likely false, as the algorithm probably makes several assumptions
Like white space word boundaries, or maybe even ascii text.
(((λ()(λ() 'yoav)))) (@yoavgo)
Agreed
 Kyunghyun Cho (@kchonyc)
this reminds me of two papers: https://arxiv.org/abs/1512.00103 (byte-level multiling processing), https://arxiv.org/abs/1610.03017 (mine)
Kyunghyun Cho (@kchonyc)
this reminds me of two papers: https://arxiv.org/abs/1512.00103 (byte-level multiling processing), https://arxiv.org/abs/1610.03017 (mine)
Emily M. Bender (@emilymbender)
Pop quiz: How many language families are represented in the test data in those papers?
Kyunghyun Cho (@kchonyc)
families, not sure. the former tested on 14 Lang's (table 1), the latter on 5
Emily M. Bender (@emilymbender)
I see 13 languages in Table 1, of which 11 are Indo-European. (The two that aren't: Finnish and Indonesian.)
Worse, those 11 include Danish & Swedish and French & Spanish & Italian. No interesting typological diffs within those sets *at all*.
For the latter paper: Russian, Czech, German and English are all Indo-European. Also: R/C and G/E are sibling languages.
Finally: You only test translating into English. Why?
Similarities between evaluated languages
 Mitch Harris (@MaharriT)
G vs E tests the whitespace word boundaries (G word formation). E by itself with whitespace vs white space. Also phrasal verbs in G & E
Mitch Harris (@MaharriT)
G vs E tests the whitespace word boundaries (G word formation). E by itself with whitespace vs white space. Also phrasal verbs in G & E
Kyunghyun Cho (@kchonyc)
computational reason :(
Emily M. Bender (@emilymbender)
You had bitext and a "language independent" model. Why not at least translate *from* English to the various other languages?
Kyunghyun Cho (@kchonyc)
we did in an earlier paper (not fully char level though): https://arxiv.org/abs/1603.06147 https://arxiv.org/abs/1601.01073
Emily M. Bender (@emilymbender)
So what stopped you from doing that this time?
Kyunghyun Cho (@kchonyc)
we could. tradeoff among (a) student leaving soon, (b) limited computational resources, and (c) was trying to focus on char-level encoder.
(a) was the biggest factor (though, @jasonleeinf is coming back to nyu from this Fall. yay!)
Djamé (@zehavoc)
that could be cool to see how good is that char model to generate complex morphological forms
Grzegorz Chrupała (@gchrupala)
Hmm, dunno French is pretty funky as far as Romance languages go innit @zehavoc
Djamé (@zehavoc)
is it ? I always thought the languages was boring but its idiosyncrasies were "kind of" fun (if you're into obscure agreement rules and such
Grzegorz Chrupała (@gchrupala)
for one, spoken French barely has any morphology.
it has this funny subject agreement system via clitics on the verb.
not your vanilla Romance
Ryan Cotterell (@_shrdlu_)
Spoken French marks verbal tense reliably through morphology, just not always person and number.
Grzegorz Chrupała (@gchrupala)
so like English
Ryan Cotterell (@_shrdlu_)
English uses periphrastic constructions for most of these. Tu parles, parlais, parleras, parlerais, parlasse are different. English has two
Grzegorz Chrupała (@gchrupala)
in spoken French a couple of these are also periphrastic, no?
and imperfect subjunctive is dead
Ryan Cotterell (@_shrdlu_)
You've have to ask someone else for that :P -- I'm only familiar with the phonology.
Emily M. Bender (@emilymbender)
This does not distinguish it from Spanish or Italian. My claim was not that French isn't interesting, just that that set is not diverse.
Spanish and Italian and Portuguese all have those clitics.
Grzegorz Chrupała (@gchrupala)
No, I mean stuff like "moi je mange, nous on mange" etc. Other Romance have object clitics, but subject agreement is done with suffixes.
Emily M. Bender (@emilymbender)
But most NLP work on French looks at written French --- which doesn't do this nearly as much.
And even if it did, you'd be *far better off* evaluating on French and Korean or Spanish and Tamil or Italian and Hausa.
Grzegorz Chrupała (@gchrupala)
Sure. But spoken/informal French is weird by Romance standards.
Kyunghyun Cho (@kchonyc)
love to eval on Korean gotta convince Samsung to release some corpora.
Djamé (@zehavoc)
What kind of Korean data set do you need? I have some free treebanks and unlabeled with sota morph analysis if you want.
Kyunghyun Cho (@kchonyc)
preferably some bitext
Djamé (@zehavoc)
you probably know it already but this is where we found the korean ressources we used for the spmrl shared tasks http://semanticweb.kaist.ac.kr/home/index.php/KAIST_Corpus
they have many bi-text corpora (chinese-english-korean, chinese-korean, etc..)
Kyunghyun Cho (@kchonyc)
not saying these papers reach a definite conclusion on the usefulness/uselessness of linguistic knowledge.
just two recent evidences that #nlproc and #ml algorithms may be pretty generally applicable across language boundaries.
Emily M. Bender (@emilymbender)
And I'm saying (again) that with that evaluation methodology, you can't really show much more than "it will run".
The longer version of this rant is available here: http://journals.linguisticsociety.org/elanguage/lilt/article/view/2624.html "On Achieving and Evaluating Language-Independence in NLP"
which is an extended version of http://www.aclweb.org/anthology/W/W09/W09-0106.pdf Linguistically Naïve != Language Independent: Why NLP Needs Linguistic Typology.
And of course, you're still assuming at least a writing system. (But you could argue that that's a fair assumption.)
Just be sure to ack that there are many languages in the world (spoken, and especially signed) without established writing systems.
(((λ()(λ() 'yoav)))) (@yoavgo)
I think a conclusion like "it will likely run ok for all Indo-European languages" is also valuable. Agree being exact in claim is better.
Emily M. Bender (@emilymbender)
Sure -- and I say as much in the paper I keep pointing to.
Kyunghyun Cho (@kchonyc)
reason why i always include finnish :)
Emily M. Bender (@emilymbender)
But including all the others without remarking on their lack of diversity as a set is not best practice.
Kyunghyun Cho (@kchonyc)
agreed. though, often this decision (which lang to include) is driven largely by the availability of data
Emily M. Bender (@emilymbender)
I'm aware of that. But even working w/the existing data, one *can* make clear statements about its drawbacks.
Kyunghyun Cho (@kchonyc)
this is perhaps the reason why nlpers should read linguistics. or at least i perhaps should..
Emily M. Bender (@emilymbender)
My point exactly! If you don't understand the data you are working with, how can you consider yourself a scientist in that area?
NLP between science and engineering
Kyunghyun Cho (@kchonyc)
well, I guess there's always diff levels of understanding that's required for each sub-field/sub-approach/...
Emily M. Bender (@emilymbender)
I'd say understanding that there are language families and that w/in a family languages tend to be similar is bare minimum for any NLP.
 Fernando Pereira (@earnmyturns)
NLP is eng, not sci; opt for dev effort, not explanation
Fernando Pereira (@earnmyturns)
NLP is eng, not sci; opt for dev effort, not explanation
Hal Daumé III (@haldaume3)
agree but dev!=engr either. must understand laws. I like https://poole.ncsu.edu/i/com/weblogs/research-development/Honing-Proposal-Skillls-1.pdf I reread this article every so often and love it every time :)
also I can't help but smile at Hazelrigg's NSF bio: https://nsf.gov/staff/staff_bio.jsp?lan=ghazelri&org=NSF&from_org=NSF
I reread this article every so often and love it every time :)
also I can't help but smile at Hazelrigg's NSF bio: https://nsf.gov/staff/staff_bio.jsp?lan=ghazelri&org=NSF&from_org=NSF
Fernando Pereira (@earnmyturns)
Laws? language ~ physics so dated; bang/$ crucial in real eng
Hal Daumé III (@haldaume3)
"Laws" maybe too strong, but understanding limits of approaches still crucial. Short term bang/$ --> hack garbage we hate in *ARPA projects
Fernando Pereira (@earnmyturns)
Engineering seeks to build useful things. Not cost-effective => not useful
 Thomas G. Dietterich (@tdietterich)
But it still benefits from scientific understanding of the fundamentals
Thomas G. Dietterich (@tdietterich)
But it still benefits from scientific understanding of the fundamentals
Fernando Pereira (@earnmyturns)
When that understanding exists/is possible.
In my experience, for NLP it only happens at the margin, more often it blocks progress
because it is wrong or too far from real problems (spherical cows).
not that many (inc me) have not tried.
maybe one day, but there are fundamental obstacles (path dependence, biosoc confounders)
Thomas G. Dietterich (@tdietterich)
So your argument is really that the science is wrong, not that it is irrelevant to engineering.
In this case, engineering may inform the science (as it often does)
Fernando Pereira (@earnmyturns)
Some very wrong, some too incomplete to help much.
Haven't seen ling depts opening their arms
Simonson (@thedansimonson)
Parts of speech: hampering progress in #NLProc since 500 BC
 Leon Derczynski (@LeonDerczynski)
What are they, really? What's the basis for them being divided up the way they are?
Leon Derczynski (@LeonDerczynski)
What are they, really? What's the basis for them being divided up the way they are?
Emily M. Bender (@emilymbender)
There's a tremendous amount of work on precisely this question in linguistic typology.
Emily M. Bender (@emilymbender)
You don't think that understanding the domain you are building things for would help build them cost effectively?
Fernando Pereira (@earnmyturns)
I do, but it's sobering how much that "understanding" has misled us -- think ASR;
started with a few "popular" langs+stat+ML, now works really well for 100s.
MT going the same way.
predictive power != explanatory power http://beginningofinfinity.com/
 Chaotic Butter Flies (@botminds)
the current engineering methods are brittle, too memory intense & data inefficient. Works by sheer force of joules. Something's still wrong
Chaotic Butter Flies (@botminds)
the current engineering methods are brittle, too memory intense & data inefficient. Works by sheer force of joules. Something's still wrong
Emily M. Bender (@emilymbender)
I'm not arguing against statistical methods! Just saying that we do better science or engineering when we understand the data.
Fernando Pereira (@earnmyturns)
Have you considered the possibility that "the data" has no concise explanation? Path dependence, random selection
Leon Derczynski (@LeonDerczynski)
After dozens of years trying to even just *model* language & failing, we can be fairly certain that the data has no concise explanation
Emily M. Bender (@emilymbender)
And neither do biological systems, but that doesn't mean that the field of biology hasn't amassed useful knowledge.
Chaotic Butter Flies (@botminds)
seems unlikely. Lang hast be learnable by young children in a largely unsupervised way. Humans have far less+less reliable working memory
than machines. Whatever structure has to be simple enough to fit in those limited noisy memories. Child like proficiency still plus useful
Concise explanations of data (added 2017-04-09)
Emily M. Bender (@emilymbender)
I'm trying to find a way to interpret this tweet that doesn't entail you dismissing the *entire field of linguistics*, and coming up empty
 Laurel Hart (@konahart)
Hot take: "the data" that tweet is referring to is itself.
Laurel Hart (@konahart)
Hot take: "the data" that tweet is referring to is itself.
 Chris Brew (@cbrew)
Indisputable that e.g. French must obey constraints sufficient to allow child to learn it from French-speaking social environment.
disputable that every child learns same French (probably not).
no reason that there should be a tidy generalization over what child A,B,C...Z learns. Only constraint is mutual comprehensibility.
space of possible objects >> space of mathematically tidy explanations.
miracle if generalization of A,B,C...Z has tidy mathematical description that is completely right.
expect strong commonalities, but not a tidy mathematical theory proceeding from few axioms to truth.
is that what you want as explanation? Never really understood the concept.
Chris Brew (@cbrew)
Indisputable that e.g. French must obey constraints sufficient to allow child to learn it from French-speaking social environment.
disputable that every child learns same French (probably not).
no reason that there should be a tidy generalization over what child A,B,C...Z learns. Only constraint is mutual comprehensibility.
space of possible objects >> space of mathematically tidy explanations.
miracle if generalization of A,B,C...Z has tidy mathematical description that is completely right.
expect strong commonalities, but not a tidy mathematical theory proceeding from few axioms to truth.
is that what you want as explanation? Never really understood the concept.
 Tim Hunter (@TimTheLinguist)
Given what "the data" means for NLP purposes, I would think most linguists probably agree that it has no concise explanation.
Tim Hunter (@TimTheLinguist)
Given what "the data" means for NLP purposes, I would think most linguists probably agree that it has no concise explanation.
Fernando Pereira (@earnmyturns)
Biology is path dependent too, simple explanations rare
but lab and evo/fossil record make progress possible, finding conserved modules.
ling closer to the lab/field can make progress
but distracted for decades by physics envy
Rob Malouf (@robmalouf)
Many (non-generative) linguists would say the same thing.
Jeremy Kahn (@trochee)
Perhaps FP means the UG project is a lost cause. That doesn't invalidate "all linguistics" except in a very syntax-centering way
Emily M. Bender (@emilymbender)
If so, his tweet was a non-sequitur. Nowhere was I talking about UG.
Fernando Pereira (@earnmyturns)
Definitely not talking about UG alone
Jeremy Kahn (@trochee)
It's hard to know what he might have meant by "concise" then; at a minimum lg encodes thought for transmission at fairly low bit rates
So, channel/source adaptive, but not random.
Thinking like @lingprof here: perhaps joint adaptation between production and perception. Concise descriptions of each still viable.
Fernando Pereira (@earnmyturns)
Concise explanation != Concise description (explanations need to be testable/potentially falsifiable)
Rob Malouf (@robmalouf)
No, but you're assuming a broadly Chomskyan view of what linguistics is. There are alternatives.
Emily M. Bender (@emilymbender)
Have you been reading my tweets? I've been promoting awareness of e.g. typological differences. Do you consider that Chomskyan?
Rob Malouf (@robmalouf)
There are plenty of typologists who I suspect would agree completely with @earnmyturns's comments. He's not dismissing them.
Practical applications of linguistics in NLP / Syntax vs. Semantics
Alex Coventry (@AlxCoventry)
What are some practical applications of linguistic knowledge which could advance contemporary NLP ML?
Fernando Pereira (@earnmyturns)
Descriptive/socio useful in collecting/preparing training/evaluation data.
experimental psycholing could help design processing models, not enough work there.
descriptive morph/syn/sem helps bootstrap systems.
but lots can be done without.
most attempts at direct application of linguistics fail badly.
but so most naive attempts at applying modern bio/omics.
big level descriptive level mismatches.
Alex Coventry (@AlxCoventry)
Has anyone tried swapping out the beam search in MT for alignment to a more elaborate generative grammar?
(((λ()(λ() 'yoav)))) (@yoavgo)
this sort of sortof what pre-neural tree2string MT (constrain search by source tree) and string2tree MT (build target with cky) did.
Emily M. Bender (@emilymbender)
There's more to ling knowledge than generative grammar. And: it can be used to advance NLP ML by improving the evaluation of NLP ML.
Apropos: https://www.nsf.gov/pubs/2017/nsf17065/nsf17065.jsp?WT.mc_id=USNSF_25&WT.mc_ev=click
Alex Coventry (@AlxCoventry)
Didn't believe or mean to imply that generative grammar is the whole of linguistic knowledge. Apologies that it came across that way.
Liling Tan (@alvations)
Has it come to a point for "Will linguistics be obsolete in #nlproc?"
 rot 13 (@zngu)
Where's the past-tense option?
rot 13 (@zngu)
Where's the past-tense option?
Alex Coventry (@AlxCoventry)
Hope it's clear that my suggestion to replace beam search w grammar alignment is the exact opposite of putting linguistics aside as obsolete
Emily M. Bender (@emilymbender)
Yes -- I didn't read it that way. OTOH, that doesn't strike me as the best way to incorporate ling knowledge into MT.
Djamé (@zehavoc)
deep syntax parsing.
Liling Tan (@alvations)
"Deep" is ambiguous here.
(((λ()(λ() 'yoav)))) (@yoavgo)
why do we need that?
Djamé (@zehavoc)
For those of us interested to know who killed Bill in "John woke up and decided it was fun to kill Bill."
Or the link between end and book in "the end Paul guessed really was the worse part of the book."
imho, the reason for which people syntax has no real benefit is bc we all use the easy subpart of it, easily emulated by n-grams and such
(((λ()(λ() 'yoav)))) (@yoavgo)
Or maybe it's because we don't really want syntax, but something else?
Djamé (@zehavoc)
An accurate approximation that can provide features to models? probably. But given the gains brought by CCG features instead of surf. dep /
I'd say we need a richer representation to extract stuff from.
Fernando Pereira (@earnmyturns)
Reason people dismiss syntax: happy with 80% in Evals [wrote: Evans, corrected in omitted subthread]
the tail 20% another story.
could go e2e to QA/inference with enough training data
but never enough training data for tail,
combinatorics see to that; syntax a scaffolding for a building that won't stand on its own
(((λ()(λ() 'yoav)))) (@yoavgo)
I agree. The only question is what this repr is. (and is raising vs control really a syntactic distinction? or a semantic one?)
Emily M. Bender (@emilymbender)
Raising v. control is a semantic distinction, but connecting the controller to the controlled argument is a syntactic matter in both cases.
Fernando Pereira (@earnmyturns)
Semantic according to some old papers of mine, but no one keeping score; whatever works
Emily M. Bender (@emilymbender)
I get the impression that you're writing off all of linguistics based on your own experience of trying to apply some of it decades ago.
(((λ()(λ() 'yoav)))) (@yoavgo)
point is I'd imagine syntax won't work.
Fernando Pereira (@earnmyturns)
CCG syn or sem?
(((λ()(λ() 'yoav)))) (@yoavgo)
Some attachment decisions require sem.
Fernando Pereira (@earnmyturns)
That's performance, not competence <ducks/>
(((λ()(λ() 'yoav)))) (@yoavgo)
in engineering we only care about performance though, right? ;)
Fernando Pereira (@earnmyturns)
Yep, if only we can find the data to train it
Grzegorz Chrupała (@gchrupala)
How do you propose to implement it? Moar treebanking?
Fernando Pereira (@earnmyturns)
Harder too, interannotator agreement falls off a cliff for less-surfacy relations
Emily M. Bender (@emilymbender)
But if you encode a lot of the info in a grammar, then a lot of this becomes much easier: http://www.mn.uio.no/ifi/english/people/aca/oe/handbook.pdf http://aclweb.org/anthology/W/W15/W15-0128.pdf
From the second of those: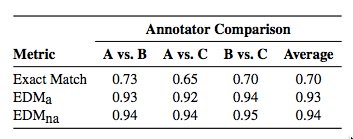
Djamé (@zehavoc)
Not that much, really. Check out this for one of our deepbanks.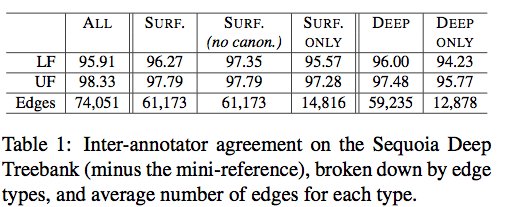 basically 1.5 pt less between deep only and surface only. http://www.lrec-conf.org/proceedings/lrec2014/pdf/494_Paper.pdf (btw, there're plenty of deep banks, cf. last CL survey)
(shameless plug for those interested : our deep treebanks are freely available) http://www.lrec-conf.org/proceedings/lrec2014/pdf/494_Paper.pdf https://hal.inria.fr/hal-01089198/document + the FQB
basically 1.5 pt less between deep only and surface only. http://www.lrec-conf.org/proceedings/lrec2014/pdf/494_Paper.pdf (btw, there're plenty of deep banks, cf. last CL survey)
(shameless plug for those interested : our deep treebanks are freely available) http://www.lrec-conf.org/proceedings/lrec2014/pdf/494_Paper.pdf https://hal.inria.fr/hal-01089198/document + the FQB
Grzegorz Chrupała (@gchrupala)
How many years of education does it cost to train an annotator? For how many languages can we build these?
The cost of annotation
Grzegorz Chrupała (@gchrupala)
How many years of education does it cost to train an annotator? For how many languages can we build these?
Emily M. Bender (@emilymbender)
It's too hard, so we're not going to do it != it's too hard so it's not interesting.
Liling Tan (@alvations)
Wouldn't it be the question of "How much of these annotations do we need?" If it's a lot, then are we learning the right way?
human languages are surely not purely "supervisedly" learnt.
Grzegorz Chrupała (@gchrupala)
Small kids don't need any of these to learn a lang, so in principle, machines shouldn't either.
Fernando Pereira (@earnmyturns)
Machines don't know how to represent the physical and social world either
nothing in language makes sense except in the light of evolution
Emily M. Bender (@emilymbender)
This argument fails unless you can also give the machines an equiv to the rich, immersive *social* environment kids experience.
Grzegorz Chrupała (@gchrupala)
Thus "in principle". We should be trying to simulate as much of it as needed.
Emily M. Bender (@emilymbender)
But ~none of the unsupervised work that I see that makes this kind of claim even notes the necessity let alone makes a baby step towards it
Grzegorz Chrupała (@gchrupala)
There is a PhD student down the corridor here working on a project titled "language learning through dialogue" so stay tuned.
Hal Daumé III (@haldaume3)
would love to see this. who is it?
Grzegorz Chrupała (@gchrupala)
Lieke Gelderloos, she's just started, so need a bit of patience. Supervised by Afra Alishahi and Raquel Fernandez.
BTW: https://twitter.com/_dmh/status/848906825307172864 ["Invited speaker Raquel Fernández will tell us about Acquiring Language through Interaction in this session of #CMCL2017"]
Hal Daumé III (@haldaume3)
cool looking forward to it!
(((λ()(λ() 'yoav)))) (@yoavgo)
wait, Raquel? did you move? did Raquel move?
Grzegorz Chrupała (@gchrupala)
No, but Amsterdam and Tilburg are near enough.
Djamé (@zehavoc)
I'd say that given the success of the UD initiative, that cost is probably factored out. But, yes of course it's expensive like hell.
Grzegorz Chrupała (@gchrupala)
CL's obsession with supervised parsing, deep or no deep, is really counterproductive. This should be a niche.
Hal Daumé III (@haldaume3)
agree. my pet peeve :)
Djamé (@zehavoc)
it is a niche.
Grzegorz Chrupała (@gchrupala)
Well then it should be more niche :-)
Djamé (@zehavoc)
that's just mean :)
Grzegorz Chrupała (@gchrupala)
No, point is lots of very smart people spent a lot of time on supervised parsing.
It may be a fun formal problem, but very little to do with language learning.
Djamé (@zehavoc)
it's bc we all believe (wrongly?) it's the key for NLU. In short, "better parsing for better tomorrows"
Grzegorz Chrupała (@gchrupala)
Good luck with that ;-)
Djamé (@zehavoc)
"a new hope" was already taken :)
Hal Daumé III (@haldaume3)
one argument: it's the simplest non-trivial structured prediction problem (I don't count seq labeling), so good testbed for ML+algo
Parsing (is a useful testbed for structured prediction)
 Michael Roth (@microth)
... but what about SRL? Have most people forgotten that the same data set has semantic annotations as well?
Michael Roth (@microth)
... but what about SRL? Have most people forgotten that the same data set has semantic annotations as well?
(((λ()(λ() 'yoav)))) (@yoavgo)
Because unlike parsing, doing SRL right requires understanding the task/data.
(and,for me, once u understand u realize how ugly it is, w/the incompatible ARG-Xs, the dependence on lexicons, impossibility of framenet..)
Michael Roth (@microth)
(Either way, I dont get why the PTB is still so popular. Why don't more researchers at least move to OntoNotes?)
Simonson (@thedansimonson)
comparability
Djamé (@zehavoc)
But that's a poor excuse. You can always include two tables with results.
FWIW Ontonotes was used for the SANCL parsing shared task but I've seen people replicating results with the PTB instead.. #FacePalm
(((λ()(λ() 'yoav)))) (@yoavgo)
what would be an even-less-trivial structured problem?
Hal Daumé III (@haldaume3)
something where there's not a 1-1 mapping between the structure and the input tokens maybe?
Ryan Cotterell (@_shrdlu_)
morphology? :P (generation and segmentation are not 1-1)
 Jacob Andreas (@jacobandreas)
semantic parsing, AMR parsing, treebank parsing with movement and empty categories, historical reconstruction
Jacob Andreas (@jacobandreas)
semantic parsing, AMR parsing, treebank parsing with movement and empty categories, historical reconstruction
Hal Daumé III (@haldaume3)
nice set!
Jacob Andreas (@jacobandreas)
OTOH AMR parsing is the kind of task you wind up with when you ignore both linguistic theory and downstream users, so maybe not best expl
Hal Daumé III (@haldaume3)
oooh feel the hurt-40.8.3-2!
Jacob Andreas (@jacobandreas)
Late to the party--in my experience it's always useful to understand why linguists care about a problem even if you don't buy the solution
Why is constituency a natural representation? - important! Does little-v exist? - not important.
What are the axes of typological variation? - IMPORTANT! (as @emilymbender said) Hypothesized consequences of pro-drop parameter?- not. etc.
(((λ()(λ() 'yoav)))) (@yoavgo)
Precisely!
Yuval Marton (@yuvalmarton)
* [likely Twitter UI fail, posted as embedding quote:]
Is constit --or did Chomsky (in very alive Xbar theory) see it as-- undivided 1st level above word/morph?(not many know answer is no)
Alex Coventry (@AlxCoventry)
Constituency == hierarchical decomposition?
 Adam Poliak (@azpoliak)
But yet it's still around and kicking. 3 AMR parsing papers at #eacl2017, shared task that just ended, and who knows how many at #ACL2017?
Adam Poliak (@azpoliak)
But yet it's still around and kicking. 3 AMR parsing papers at #eacl2017, shared task that just ended, and who knows how many at #ACL2017?
Jacob Andreas (@jacobandreas)
I shouldn't be too mean-it's a fun struct pred task and I think we've learned things about graph parsing that carry over to other formalisms.
But hasn't turned out to be the promised interlingua
Adam Poliak (@azpoliak)
I can see AMR one day being incorporated in some MT evaluation to measure semantic similarity. I guess then I'm all for work in AMR parsing.
After a semester trying to generate RTE from a given AMR parse, I find it hard to buy that AMR is THE sembanking solution
Emily M. Bender (@emilymbender)
Have you looked at Redwoods? Probably best intro at this point is our tutorials from LREC & NAACL last year: http://moin.delph-in.net/ErsTutorial
This is an English resource, though there are similar, smaller (not broad coverage) resources in a handful of other lgs.
Djamé (@zehavoc)
RTE? btw, has someone published a solid criticism of AMR? I still don't get why it's trending more than deepbanks like DM (stanford effect?)
Adam Poliak (@azpoliak)
Recognized Textual Entailment. I prob should've just said textual entailment
Emily M. Bender (@emilymbender)
This paper is in part a criticism of AMR: http://aclweb.org/anthology/W/W15/W15-0128.pdf
brendan o'connor (@brendan642)
What's DM? There was (recently?) lots of funding for AMR which IMO is part of why there's been so much work on it recently.
oh, DM=dep version of HPSG/MRS, right.
one result of the fact semeval2014 task 8 did 3 different non-amr formalisms (2 being hpsg-related!) is, i keep getting them confused...
Djamé (@zehavoc)
they needed this to benchmark those annotation schemes. The Prague-based one proved too difficult to parse, they had to change it in 2015
(((λ()(λ() 'yoav)))) (@yoavgo)
you forgot non-projective parsing, universal-dependencies parsing, stanford-dependencies v3.3.0 parsing ;)
Hal Daumé III (@haldaume3)
i wouldn't say non-proj nor UD fits that list (at least my categorization) unless i'm wrong about those formalisms (entirely possible :P)
(((λ()(λ() 'yoav)))) (@yoavgo)
my point was that these are all subtypes of parsing. sem-parsig is a bit different, but really depends on how you pose the problem.
Hal Daumé III (@haldaume3)
but not really structurally different from a SP perspective? although isn't Stanford dependencies a DAG?
Emily M. Bender (@emilymbender)
So are MRS representations (semantic layer of the Redwoods treebank).
(((λ()(λ() 'yoav)))) (@yoavgo)
the "complete" stanford-deps is a DAG, I think UD also supports non-tree elements. The "real" parsing tasks is with the empty elements.
Hal Daumé III (@haldaume3)
ah ok cool. thanks!
(((λ()(λ() 'yoav)))) (@yoavgo)
we have been doing a reduced version of parsing for a while (PTB without the hard parts), but that doesn't define the task imo.
I think the cool thing about syntax is that you can go a long way *without* requiring domain-specific fine-grained semantics
so supervised is actually a good approach for this. of course, there are many syntactic things we currently do not do well still.
they are all bordering on "semantics" to varying levels, but are still also quite structural. For example empty elements, or coordination.
(and I am trying to go there with some of my students' research, cf @JessicaFicler 's line of work on coordination, and more coming soon)
Emily M. Bender (@emilymbender)
Still looking at PTB? Would you be open to a more linguistically motivated treebank, like Redwoods?
Redwoods
Emily M. Bender (@emilymbender)
Still looking at PTB? Would you be open to a more linguistically motivated treebank, like Redwoods?
(((λ()(λ() 'yoav)))) (@yoavgo)
For coordination, we fixed the PTB a bit. For other cases, we will likely annotate them specifically. Will look at Redwoods.
Emily M. Bender (@emilymbender)
Feel free to use me as a point of contact for Qs about Redwoods
(((λ()(λ() 'yoav)))) (@yoavgo)
So, I found the project page and got lost. How do I go about downloading and looking at the trees?
Emily M. Bender (@emilymbender)
It looks like our documentation is a bit out of date. I'll see if I can get people to update it.
Meanwhile, you can find a release of DeepBank (same text as the PTB) here: http://metashare.dfki.de/repository/browse/deepbank/d550713c0bd211e38e2e003048d082a41c57b04b11e146f1887ceb7158e2038c/
Some explanation of that here: http://moin.delph-in.net/DeepBank
The page where I expect to find the most up to date treebanks is this one: http://moin.delph-in.net/RedwoodsTop
But that one still talks about 2011. I'll see what I can find out.
(((λ()(λ() 'yoav)))) (@yoavgo)
I clicked on "download" and it said I need to contact someone, and when I clicked that it said I should open an account, via a scary form.
can you point to a download link that actually allows to download? or, like, email me some files? (first.last@gmail)
Emily M. Bender (@emilymbender)
Yeah, that's not very friendly. Hang on...
Okay, so the reason this is complicated is that the actual treebanks include quite a bit of info you don't want to see:
Derivations (the recipe for reproducing the full trees with avms, given a grammar) as well as the semantic representations.
There are scripts for creating various export formats, given that input, but very little stored (as yet) in the export formats.
I found some here (from WikiWoods), but note that these files are *huge* and they represent automatic parse selection, rather than manual.
Here = http://ltr.uio.no/wikiwoods/1212/
Info on how to export to the plain text formats: http://moin.delph-in.net/WeScience
The latest release of the treebank seems to be in the tsdb/gold directory with the 1214 grammar release here: http://svn.emmtee.net/erg/tags/1214/
I can look more into sending you samples, but first I guess I'd like to know which export format you're interest in.
Do you want syntax trees with PTB-style node labels? Syntax trees with our native labels? Full semantic reps? A variable-free reduction?
The ERS tutorial has some more info on the various formats for the semantic representations: http://moin.delph-in.net/ErsTutorial
Not represented there, but now possible: a penman-style (i.e. AMR-lookalike) serialization.
(((λ()(λ() 'yoav)))) (@yoavgo)
is there a place where I can browse the trees online and see which information is there? I don't know what I want yet, just to look around.
 Stephan Oepen (@oepen)
semantic graphs from DeepBank 1.1 (ERG 1214) available for download in a variety of formats: http://sdp.delph-in.net/index.php?page=5
Stephan Oepen (@oepen)
semantic graphs from DeepBank 1.1 (ERG 1214) available for download in a variety of formats: http://sdp.delph-in.net/index.php?page=5
Emily M. Bender (@emilymbender)
Yes -- through the online demo: http://erg.delph-in.net . Put in a sentence and see what comes out :)
Try checking 'mrs' (unchecked by default) to see the full semantic representation.
These will come up as ranked by the parse selection model, i.e., you're talking to a parser not a treebank.
But it's the same kind of representations as you would get from the treebank.
Actually: There's one missing. That demo doesn't show the native derivations, but rather the relabeled trees.
If you mouse over the node labels on the trees, though, you'll see the native node labels, which are rule identifiers.
(((λ()(λ() 'yoav)))) (@yoavgo)
I tried "john hates and mary likes wine" and got nothing back --- am I doing something bad or is it just a hard case?
Emily M. Bender (@emilymbender)
Hard case ;-) The ERG does some right node raising, but I guess not like that.
Try: John saw and talked to Mary.
Parse #2 looks like the reading I had in mind.
(((λ()(λ() 'yoav)))) (@yoavgo)
cool, thanks!
Alex Coventry (@AlxCoventry)
Is there a way to get partial parses from ungrammatical sentences? E.g. "What is the step by step guide to invest in share market in india?"
returns no parses, but "What is a step-by-step guide to invest in the share market in india?" does.
Emily M. Bender (@emilymbender)
There are robust processing options that can be turned on if you are running the parser yourself,
But I think these aren't switched on in the demo.
Screw parsing?
Grzegorz Chrupała (@gchrupala)
It's a case of a testbed taking a life of its own
Hal Daumé III (@haldaume3)
oh i agree. it amazes me how much we love parsing, as evidenced by fraction of best papers that go to that topic
i wonder if deep learning will now kill off low level tasks like pos tagging, parsing, etc. why parse---just bilstm (or cnn or whatever)
Simonson (@thedansimonson)
well, for one, parser-ouput is useful for capturing script knowledge and/or narrative knowledge.
even @kpich and Mooney's work on using an LSTM for learning script knowledge requires a pre-parse to capture events.
in a lot of unsupervised contexts, having a parser handy is good for discovering features
 Omid Bakhshandeh (@omidbbb)
I think it all depends on the task and how much data you have (e.g. Winograd Challenge vs.CNN/Dailymail).
it's kinda amazing that people here think that there will be labeled data for everything and linguists think the other way!
NLP pipeline is the only theory we currently have for small data NLU end tasks, the idea is:
get the sentence closer to its semantic structure and then we give you some guarantees that you need less data to solve your NLU task
I am agnostic about the semantic structure, it can be a tensor or a graph or both!
Omid Bakhshandeh (@omidbbb)
I think it all depends on the task and how much data you have (e.g. Winograd Challenge vs.CNN/Dailymail).
it's kinda amazing that people here think that there will be labeled data for everything and linguists think the other way!
NLP pipeline is the only theory we currently have for small data NLU end tasks, the idea is:
get the sentence closer to its semantic structure and then we give you some guarantees that you need less data to solve your NLU task
I am agnostic about the semantic structure, it can be a tensor or a graph or both!
Grzegorz Chrupała (@gchrupala)
POS tagging, most likely. Parsing may be too entrenched, may take a whole generation of researchers who built their careers on it to retire.
Kyunghyun Cho (@kchonyc)
or by a new gen of PhD students of theirs
Grzegorz Chrupała (@gchrupala)
fwiw, my phd was on supervised tagging / parsing, but i'm over it now :-)
Hal Daumé III (@haldaume3)
agree. they often sit on best paper committees.
I also wonder how tied this is to English bias
or at least English + Indo-European
Kyunghyun Cho (@kchonyc)
morph seg or word seg equiv. to post tagging?
(((λ()(λ() 'yoav)))) (@yoavgo)
I'm not convinced that biLSTM can wholly replace syntax. for the shallow stuff, sure, but for the more intricate ("deep") cases its trickier
even for something as simple as SV agr in English, our work with @tallinzen shows that LSTMs can capture it well, but need explicit signal.
so its will not just "evolve" from the task, even from related tasks like LMs, and needs to be told what to look for (using, ahm, syntax).
(also, despite the high accuracy of the LSTM on this task, I still think a parser-based model will do better than the LSTM on this)
also, still preliminary results, but a recent ACL paper with @roeeaharoni shows we can improve NMT with target side syntax. so there's that.
Grzegorz Chrupała (@gchrupala)
Cool.
Alex Coventry (@AlxCoventry)
When the preprint's available, I'd love to read it.
 Roee Aharoni (@roeeaharoni)
Thanks, out very soon!
Roee Aharoni (@roeeaharoni)
Thanks, out very soon!
Grzegorz Chrupała (@gchrupala)
Multitask learning, plus a reasonably strong prior on the nature of the structure could get you all the way there, hopefully.
But yeah, I'd say the prior is best given by using model less agnostic than LSTM.
None of this alleviates my skepticism of supervised parsing.
(((λ()(λ() 'yoav)))) (@yoavgo)
prior on nature of structure comes from supervision, I assume? so its still supervised parsing to some extent, in my view.
Grzegorz Chrupała (@gchrupala)
Not necessarily, it can come from the functional form of the model, no?
Fernando Pereira (@earnmyturns)
How many bits in language learner prior? Count carefully
A prior on the nature of structures
Fernando Pereira (@earnmyturns)
How many bits in language learner prior? Count carefully
Grzegorz Chrupała (@gchrupala)
Size of the genome is the upper bound.
(((λ()(λ() 'yoav)))) (@yoavgo)
why?
Grzegorz Chrupała (@gchrupala)
Where else would the prior be encoded? We're talking stuff common the whole species, not language specific.
(((λ()(λ() 'yoav)))) (@yoavgo)
physics?
Grzegorz Chrupała (@gchrupala)
How?
(((λ()(λ() 'yoav)))) (@yoavgo)
in guiding the interactions of components specified in dna?
Grzegorz Chrupała (@gchrupala)
Isn't this like including the laws of the physics in accounting for the information content of a cake recipe?
(((λ()(λ() 'yoav)))) (@yoavgo)
the knowledge of baking a cake contains the knowledge of creating even heat etc, which is encapsulated in the oven's mechanics.
Grzegorz Chrupała (@gchrupala)
Yes, ultimately we need all of science to understand how to make a cake. Not sure this is a meaningful way of quantifying size of recipe.
(((λ()(λ() 'yoav)))) (@yoavgo)
just saying, knowledge could be more than the recipe alone.
Grzegorz Chrupała (@gchrupala)
For the record, not saying knowing the DNA sequence = knowing the prior. That's obviously wrong: we do know the DNA and we don't the prior.
Rather arguing that, contra Fernando, the prior's encoding could be reasonably compact.
 Christopher Manning (@chrmanning)
But also, which set is bigger: linguists who understand why sequence models are so successful or NLP people who know/like/use linguistics?
Christopher Manning (@chrmanning)
But also, which set is bigger: linguists who understand why sequence models are so successful or NLP people who know/like/use linguistics?
(((λ()(λ() 'yoav)))) (@yoavgo)
In which of these groups do you belong? ;)
Kyunghyun Cho (@kchonyc)
tricky..
This completes our walk through this huge thread. I for one am looking forward to the next one... but I hope that by then someone™ will have created a nicer way to read them.
Finally, please let me know if I missed or misrepresented your tweet, so I can fix that! :)
- https://twitter.com/bullethq_botty/status/848611016757964801
- https://twitter.com/cohenrap/status/848380775129120768
- https://twitter.com/StefanMuelller/status/848744934593228802 and children
- https://twitter.com/emilymbender/status/848608704375083008 (added as note)
- https://twitter.com/yoavgo/status/849151977099493377 (quotes same thread)
- https://twitter.com/StefanMuelller/status/849624721582956544 and children (book publishing question)
- https://twitter.com/yoavgo/status/849155734604480512 ("gotta run")
- https://twitter.com/yuvalpi/status/848667757369581569 (Paging Doctor @Ari_Deez")
- https://twitter.com/haldaume3/status/848677438955679744 (joke... I think)
- https://twitter.com/trochee/status/848680264934936576 and children
- https://twitter.com/yoavgo/status/849274094088585217 ("link?")
- https://twitter.com/haldaume3/status/848587855458906114 (duplicate agreement)
- https://twitter.com/yoavgo/status/848639032028536833 ("damn Twitter interface")
- https://twitter.com/i_am_erip/status/848837072597155840 (joke)
- https://twitter.com/yoavgo/status/848806894441566209 (typo correction)
- https://twitter.com/AlxCoventry/status/848929331112030212 and children (ahm == uhm)
- https://twitter.com/bullethq_botty/status/848911738531610625 (spam)
- Update 2017-04-09: https://twitter.com/themitcho/status/849040719624904704 (defending a twitter like)