Language diversity in ACL 2004 - 2016
2016-12-22A couple days ago I posted a tweet asking the provocative question "Natural Language Processing == English Language Processing?" and presenting the initial results of some counting I did. The high number of 69% of ACL 2016 long papers that only evaluate on the English language seemed to be interesting to quite a few people, so I decided to continue counting and building a couple more nice plots.
Since all ACL conference proceedings are open-access and available, it's easy to download all[1] papers from ACL 2004, 2008, 2012 and 2016 and take a look at the languages they're evaluating on (more about my methodology after the charts).
Only English?
To pick up where my tweet left, let's ask this simple question again: how many papers only evaluate on English?
 As we can see, 1) the ratio is pretty high and 2) it hasn't really changed that much in the last decade.
As we can see, 1) the ratio is pretty high and 2) it hasn't really changed that much in the last decade.
Popular languages
Apart from answering this simple enough question maybe we should take the time and look at the collected data a little more. We might ask how many languages papers usually evaluate on and what languages these are:

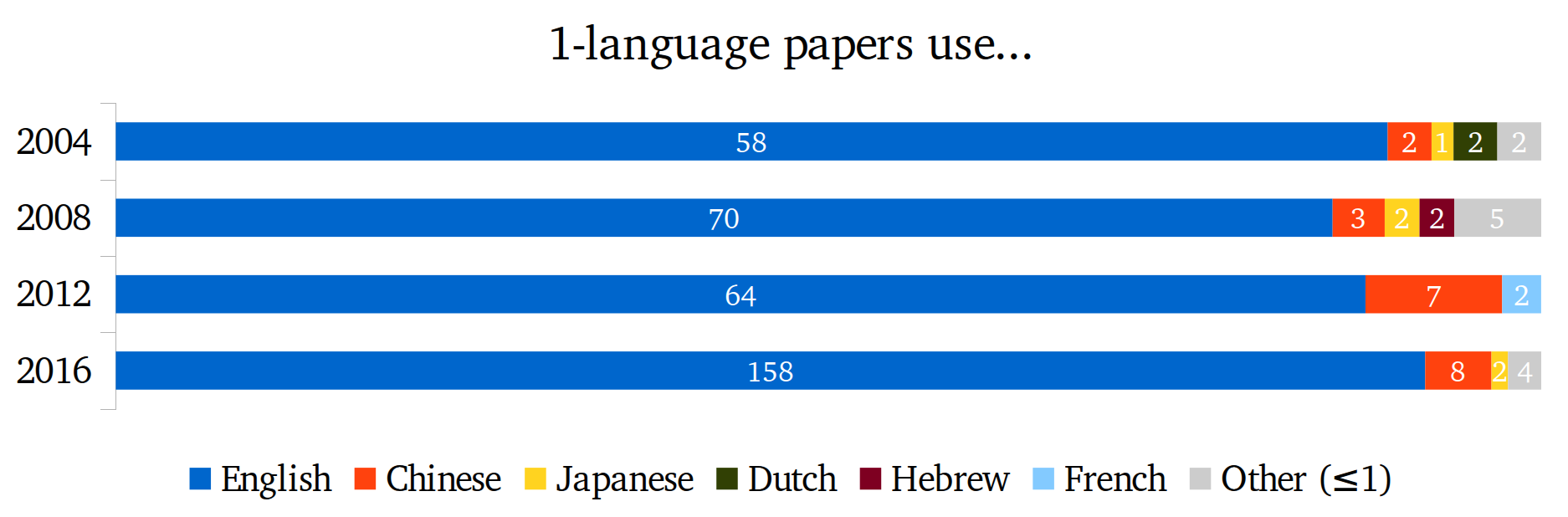
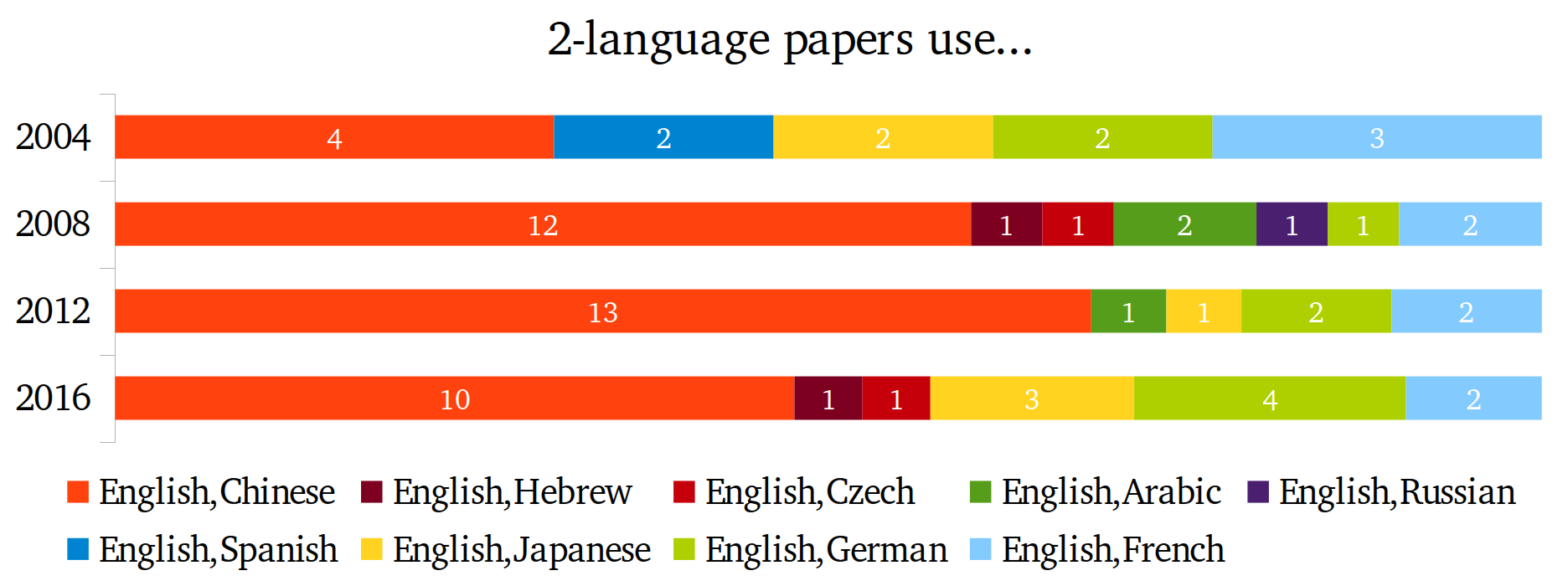
Looks like English is the champion of 1-language papers and even the truly undisputed "champion" of 2-language papers as well: I didn't find a single 2-language paper that did not use it. We can also clearly see that Chinese is not only the second-most popular single language in 1-language papers, but also the most popular second language in 2-language papers.
So let's close this question with a little group picture with all languages[2]:
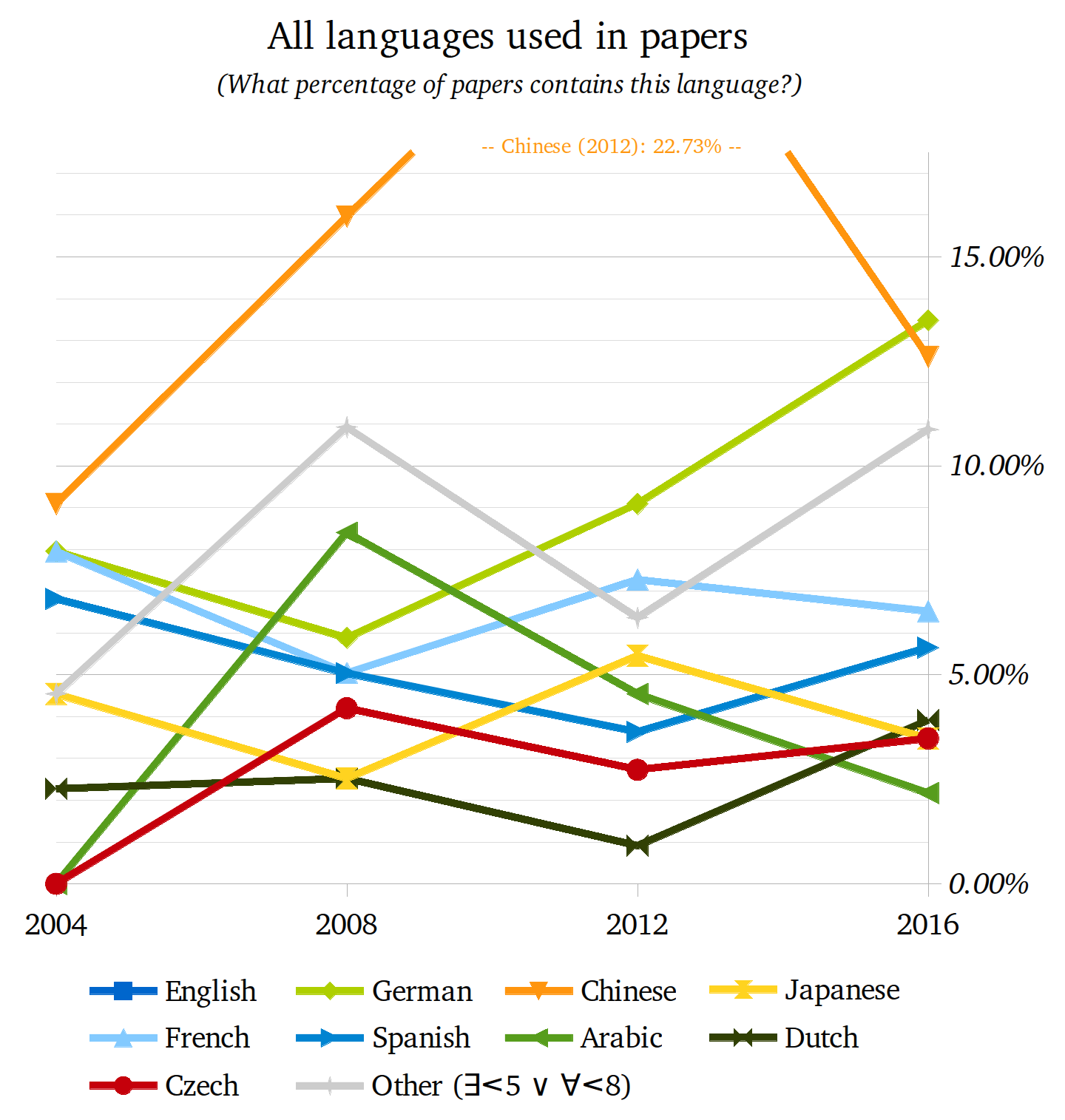
Language diversity
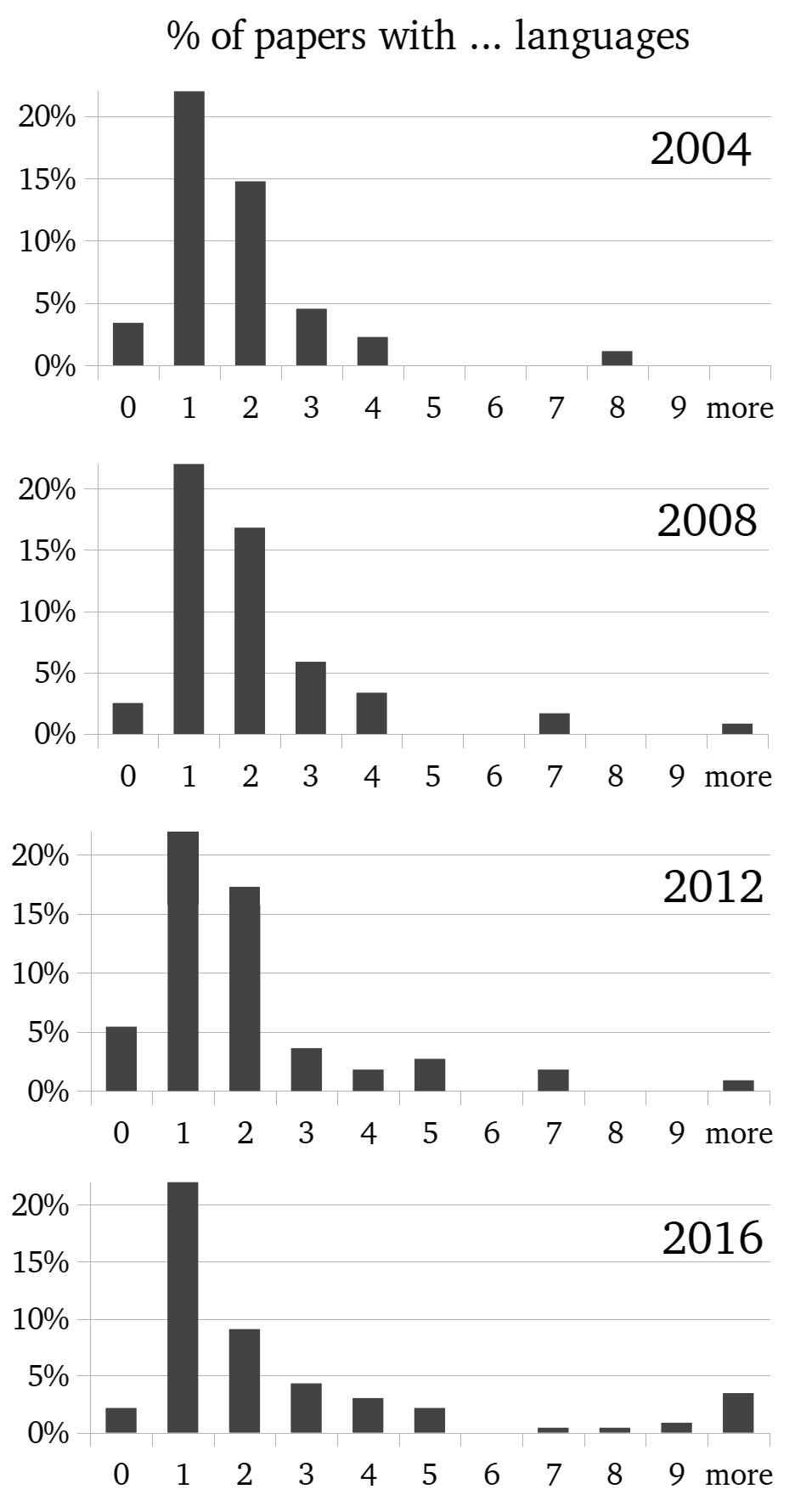
Now that we know what the popular languages are - what about the "long tail"?
In the distributions on the left, we can see the percentage of papers with n languages[3] over the years. Over the years, more papers with more languages appear; in 2016 we can see a decline in the number of 2-language papers.

We can also see the described effect very nicely when plotting the average number of papers and the standard deviation, as above: the number of 1-language may stay the same or even grows, but the number of papers with a lot of languages grows.
An unquantified/unqualified impression
So much for the facts, but what about the original question about the ratio of English-only papers? Their number seems to be mostly determined by the existence of data sets. In 2004, not that many non-English sets seemed to exist or be popular; a fact that is perhaps slightly remedied by multilingual CoNLL tasks for 2008 and 2012? In 2016 we have much more English-only papers again - is it thanks to new tasks emerging for which we only have English sets again? Are people lazy? Is it deep learning's fault? Or is there some other reason - perhaps related to the roughly doubled number of long papers over 2012[4]?
Sadly these kind of questions seem harder to answer with my simple counting than I hoped. In fact, I feel the reading itself was much more interesting than the numbers I punched into my spreadsheet. Especially for me as a newbie to the whole field it was interesting to see the radical changes: data sets, methods and of course buzzwords:
2004 often doesn’t seem so data driven at all yet, quite a few papers make use of the English Resource Grammar and popular data sets that are used include ACE, MUC, TREC[5] data and of course the ever-popular (sigh) WSJ part of the Penn Treebank. Fun fact: there are even a handful of papers using “neural networks”.
Over the following years it feels like we're seeing more established tasks and methods. Multilingual CoNLL data sets appear more often and MT papers happily use europarl to compare more than just two languages. 2012 papers seem dominated by Bayesian methods and graphical models, and 2016 of course seems to be all about neural nets.
While being able to quantify this impression of mine would be nice, I felt it would be difficult to really get reliable numbers - and a reliable method of counting. And that leads me to the caveats of this counting process.
Notes about my counting process
Counting papers is surprisingly difficult. As Emily M. Bender explains, most authors seem to assume that English is a "representative" language and that methods that are not explicitly created with English in mind should perform just as well on other languages as they do on English.[6]
Regardless of whether that's true or not, it can make the job of counting papers harder if these authors choose to forego the question of language choice altogether. Often authors would just state that they evaluate on some corpus, forcing you to follow its trail and determine its language[7]. Some hide explanatory parentheticals[8] in unrelated paragraphs. Only few papers were as easy to read as I initially hoped.
Especially compared to the aforementioned analysis from 2008 my counting is also quite primitive. I neither grouped languages into language families (that's depressing anyway), nor did I do a fine-grained separation into 1) papers that work with the relation between multiple languages (like machine translation) and 2) "monolingual" papers that merely evaluate on multiple languages separately (like syntactic parsing). Perhaps that would be nice and interesting, but I fear that this separation might be difficult to uphold for some edge cases[9].
The good news is: despite all sources of ambiguity[10] my counts line up pretty well with Emily M. Benders aforementioned counts of ACL 2008, so it seems that sufficiently consistent choices are possible.
Careful with that interpretation, Sabrina
Apart from the problems arising from my counting methodology, there are a few things to keep in mind about this data when trying to draw conclusions.
I only "sampled" four years to limit the amount of counting I had to do, assuming that these are representative enough while spanning a long time.
Likewise, with ACL I tried to select a representative conference, but of course ACL is by far not the only interesting conference. While EMNLP and LREC may fill slightly different niches, I am a little worried about the influence of NAACL and EACL. Might NAACL have "drawn out" some English papers in 2004, 2012 and 2016 - or likewise might EACL have gotten some non-English papers in 2012 that did not appear at ACL? Again, I don't think I am qualified to answer that question.
So what now?
To all authors: pleeeeeease be more explicit about your languages. Just one word can help a person that does not yet know "well known" corpora (like Switchboard etc.). To all data set creators: don't be afraid to try using other languages than English! If you really want to work on languages and problems (and not just on one specific DARPA evaluation), one language is a little sad.
And to the enthusiastic reader: if you're excited about counting papers, too, now, I guess, I didn't really bring my message across ;) But perhaps you are interested in getting some more info out of the data or have much better and more interesting questions than me!
You can find all the raw data here (OpenDocument spreadsheet), please feel free to take a look at everything! I'd be very happy to hear about your point of view... and as a starting grad student I'm very grateful for feedback on this piece, so see you on Twitter :)
Update (2017-09-23):
After Hal Daumé III asked on Twitter, people pointed to more resources, namely (in addition the aforementioned 2013 paper by Emily M. Bender) this short and interesting blog post on language representation in ACL 2015 by Robert Munro. Thanks!
Please feel free to cite this post using BibTeX like this:
@misc{
Mie2016Language,
title={Language diversity in {ACL} 2004 - 2016},
url={https://sjmielke.com/acl-language-diversity.htm},
author={Sabrina J. Mielke},
year={2016},
month={Dec}
}
I left out P12-1102 and P16-1038, because both of them consider more than 200 languages - too much for my little charts. ↩
Those that do not appear at least 5 times in every year and at least 8 times at least once are grouped as "Other". ↩
We already saw that 1-language papers are at ~80% and are thus cut off in these graphs. ↩
2004: 88, 2008: 119, 2012: 110, 2016: 230 ↩
Automatic Content Extraction, Message Understanding Conference and Text REtrieval Conference, respectively ↩
I still went ahead and classified most KB/ontology work as English, counting WordNet, Freebase etc. as specifically English-language resources. ↩
"Our dataset is a collection of 272 oral history interviews from the MALACH collection." Guess what the M in MALACH stands for. Still a little unsure about this one. ↩
Like "(One note here: throughout the paper we work on English to Japanese translation)". ↩
Consider a paper that present a new language model for machine translation. Are both languages of the translation process relevant or only the target language (for which the language model is developed)? ↩
Another example: what do you do with a paper that off-handedly tells you it also "successfully" evaluated on some other language? And if you do include it, what about the third language that they aren't done with but that seems "promising"? ↩